Stop using Knex.js
Using SQL query builder is an anti-pattern
This is true about any SQL query builder. I chose to use knex.js as an example because it is the most popular SQL query builder in the Node.js ecosystem and we need an example.
tl;dr; Knex.js (and other query builders) was designed to be a building block for ORMs; it does not add value when majority of the query is static.
If you are evaluating alternative to Knex.js, I have since published another article discussing how to build queries using Slonik.
Update 2022 October:
3 years have passed, and this article remains as relevant and as controversial as it was on the day it was published. While the article is titled Knex.js, it applies to all trending query builders that encourage to write anything but raw SQL.
Abstract
My biggest beef with any query builders is that they add an unnecessary level of abstraction on top of what is already a language designed specifically for creating-reading-updating and deleting data. JavaScript is not designed for this.
SQL is used by tens of thousands developers. SQL developers will understand the intent at a glance. Writing plain SQL allows developer to quickly copy and paste code between IDE and SQL prompt for testing and development.
SQL has been around since 1974 and it is a standardised and more or less stable language. SQL query builders come and go.
SQL query builders are specific to the programming language that you are working with; SQL is a universal dialect that you can use from any programming language.
I would be fine with SQL builders if there was a clear benefit, e.g. it added a layer of security or made the code more testable. However, as I demonstrate in this article, none of this is true (or at least not more true than what can be achieved with a well designed SQL client).
To sum up, I recommend that you use a query builder for those few queries that need to be generated dynamically, and use raw SQL for everything else. It is not one or the other; the two work together.
Disclaimer:
I am the author of Slonik – Node.js client for PostgreSQL that promotes writing raw SQL and discourages ad-hoc dynamic generation of SQL.
Survey
I surveyed developers to find out their reasons for using Knex.js and summed up their answers. Let us go through them one by one. Where relevant, I will include analogous examples written using Knex.js and Slonik.
“Knex.js allows to use language-native types and syntax for constructing queries”
Let us say that you know SQL and you have a problem to solve, such as “I need to get all records from table person where first_name is equal to potentiallyUnsafeUserInput.”
To solve this problem, you first need to answer “What query do I need to execute to get this result?” You might even begin by writing the query in your SQL editor and try it to ensure that it gives the result that you desire.
SELECT id
FROM person
WHERE first_name = 'foo'Now that you have a query, and since you are using a query builder, you need to take a step back and answer “How do I build this query using Knex.js?”
knex('person')
.where({
first_name: 'foo'
})
.select('id')This extra step would only make sense if rewriting the query in Knex.js had extra benefits, e.g. if the query built and executed using Knex.js had a more efficient execution plan. But that is the role of ORMs; Knex.js is a 1-to-1 query builder. Furthermore, this extra step is particularly painful if you are working in a large team with an access to a DBA. A DBA is not going to know Knex.js.
In the above example, the query is static (the structure and values of the query do not change) — there is little benefit in using a query builder.
“Knex.js allows to build queries with dynamic conditions”
In principal, I buy this. Knex.js does indeed allow to construct queries in way that is a native to JavaScript, e.g.
let query = knex('person');if (userInputFirstName) {
query = query.where({
first_name: userInputFirstName
});
}if (userInputLimit) {
query = query.limit(userInputLimit);
}
I think this is a big reason to use Knex.js.
However, if you are going to be allowing user’s input to dictate the shape of the query, then this must be carefully planned and throughly tested.
Therefore, allow me to propose an alternative: What if you could completely isolate generation of the dynamic query fragment instead? This is what Slonik sql.raw allows you to do.
const createWhereFragment = (firstName: string) => {
if (firstName) {
return sql.raw('WHERE first_name = $1', [firstName]);
} return sql.raw('');
};const createLimitFragment = (limit: number, offset?: number) => {
if (offset) {
return sql.raw('LIMIT $1 OFFSET $2', [limit, offset]);
} return sql.raw('LIMIT $1', limit)
};const query = sql`
SELECT id
FROM user
${createWhereFragment(userInputFirstName)}
${createLimitFragment(userInputLimit)}
`;
The benefit of the latter approach is that it clearly separates the static and dynamic parts of the query and unit tests can be written separately just for the dynamic components of the query.
I prefer the createWhereFragment and createLimitFragment approach. However, in practise, if I need to build a dynamic WHERE or LIMIT, I would use Knex.js for that particular query or a sub-query that restricts the statically typed query results.
“Knex.js is safe by default”
I assume that “safe by default” means that one needs to go out of its way to use it unsafely, e.g. use knex.schema.raw(statement).

Suppose that we have a variable potentiallyUnsafeUserInput that contains any user input. We want to construct a query that uses the value of this variable in a WHERE condition.
Knex.js parameter binding
In Knex.js you would write it as:
knex('user')
.where({
first_name: potentiallyUnsafeUserInput
})
.select('id')Knex.js generates:
SELECT "id" FROM "user" WHERE "first_name" = $1I agree with the general premise, that Knex.js API guards user from unsafely interpolating user-input.
Unsafe example
If you are wondering what would be an unsafe example, consider if you were to construct the SQL yourself, e.g.
'SELECT id FROM user WHERE first_name = \'' + potentiallyUnsafeUserInput + '\'';In the latter case, if potentiallyUnsafeUserInput value was '; DROP user; ' then you would create an SQL injection (assuming that the SQL client allows to execute multiple queries).
Slonik: sql tagged template literal
However, we can enjoy all the same benefits without Knex.js. Using Slonik, you simply write the query using sql tagged template literal, e.g.
sql`SELECT id FROM user WHERE first_name = ${potentiallyUnsafeUserInput}`The result of the above is:
{
sql: 'SELECT id FROM user WHERE first_name = $1',
values: [
potentiallyUnsafeUserInput
]
}Query and the parameter values are going to be sent in a separate protocol message (Parse and Bind respectively; read Extended Query protocol).
There is no risk of user accidentally forgetting to use parameterisation: Slonik only executes queries that are generated using the sql tagged template literal.
The side benefit using sql tagged template literal is that you get syntax highlighting and built-in linting.
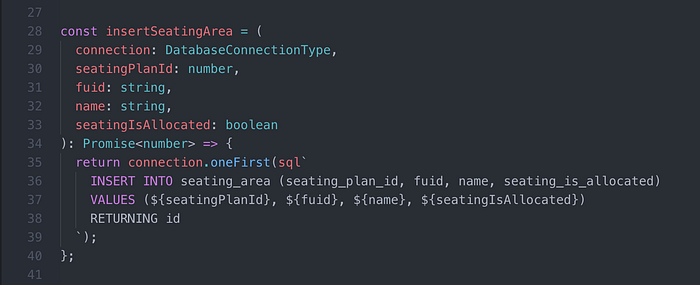
“What about the identifiers?”
Suppose that potentiallyUnsafeUserInput describes a table or a column name. SQL identifiers cannot be parameterised. Therefore, we must interpolate the user input into the query. This is true for Knex.js and Slonik.
The unsafe way would be:
'SELECT "' + potentiallyUnsafeUserInput + '" FROM "user"';Knex.js is:
knex('user')
.select(potentiallyUnsafeUserInput)Assuming that potentiallyUnsafeUserInput is equal to “foo”, then Knex.js generates:
SELECT "foo" FROM "user"There is no magic behind how the identifier is escaped. Escaping an identifier is simply:
'"' + identifier.replace(/"/g, '""') + '"'However, remember that Slonik only accepts queries that are generated using sql tagged template literal. Therefore, you cannot mimic the earlier unsafe example. Slonik builds SQL using tokens. In the first example (binding a value in the WHERE first_name condition), we saw Slonik replace a primitive value expression with $1 positional parameter binding. And in this example, we can use sql.identifier to tell Slonik to interpolate an identifier, e.g.
sql`
SELECT ${sql.identifier([potentiallyUnsafeUserInput])}
FROM "user"
`The result is:
{
sql: 'SELECT "foo" FROM "user"',
values: []
}sql.identifier is just one token generator. Slonik includes many:
and I am designing an API that will allow to bring-your-own tokens.
“Using Knex.js reduces the SQL learning curve”
Just to play a devil’s advocate, I am going to say, if I am a junior developer who has never worked with anything but JavaScript and I need to create a table for storing information about persons and then write a query to retrieve all persons by their first name. It is reasonable to think that just by reading Knex.js documentation I am going to quicker come up to the solution to the initial problem, e.g.
knex.schema.createTable('users', (table) => {
table.increments();
table.string('first_name');
});knex('person')
.where({
first_name: potentiallyUnsafeUserInput
})
.select('id');
Next, you need to add a new column to table user. You search through the documentation and find no answer. Your search Google “Knex.js add column”. No answer. You start searching and asking in the SQL community, but SQL community does not know Knex.js.
The same applies to any SQL error that you might get. It will be an SQL error, not Knex.js error. You absolutely do need to know SQL in order to work with the database. By doing it through Knex.js, you are only increasing the learning curve by learning two things at the same time (one of which you will realise years later is not necessary).
SQL is already a language designed to perform CRUD operations. There are tens of thousands DBAs/developers capable of writing SQL. When planning for the learning curve, consider what are the odds that a new developer that you brought to your fast growing team is going to know SQL vs that he is going to know Knex.js?
“Knex.js allows to compose together partial queries”
Whatever was meant by this, you can compose queries using Slonik.
const query0 = sql`SELECT ${'foo'} FROM bar`;
const query1 = sql`SELECT ${'baz'} FROM (${query0})`;Produces:
{
sql: 'SELECT $1 FROM (SELECT $2 FROM bar)',
type: 'SQL',
values: [
'baz',
'foo'
]
};One could argue that because Knex.js is context aware, that you will not be able to construct a query that would produce a syntax error (without using raw). That is hardly an argument to add the extra layer of abstraction: You will make thousands of SQL syntax errors as you develop queries. No harm done.
“Knex.js allows to migrate between different SQL dialects”
If you are building software from the first day with a consideration “What if we are going to need to migrate from MySQL to PostgreSQL?” then there is something fundamentally wrong with your technical planning.
Migrations of existing projects from one database dialect to another happen extremely rarely. In all my professional career, I have not seen an attempt to migrate an existing codebase to a different database backend.
I have seen cases where it was desirable to migrate from one backend to another (e.g. due to high licensing costs). However, the effort that was required to migrate the codebase was deemed greater than the cost of gradually adopting the new database.
The truth is that that anything but a simple TODO application is going to require major effort to migrate schema, data and procedures. There will be multiple applications talking to the same database, therefore the complexity is spread across multiple, including legacy, codebases. Knex.js being able to rewrite simple queries to a different dialect (but not those that use whereRaw, joinRaw, havingRaw, groupByRaw, orderByRaw or raw) is going to be the least of anyone’s concern.
“Knex.js abstracts transaction handling”
This comment refers to knex.transaction method. This method accepts a query and executes the query using transaction, i.e. BEGIN; SELECT your_query(); and depending on whether your_query() successfully executed or not, COMMIT or ROLLBACK.
For starters, as the name suggests, this is not what an SQL builder is supposed to do. This goes into the domain of query life-cycle handling. Other than that, this feature is natively supported by every major SQL client, e.g. see Slonik transaction method.
“Knex.js strict types warn about errors”
It warns about Knex.js API errors, not SQL errors. If you use Knex.js, you didn’t have this problem.
Is there a use case for Knex.js?
Yes: Creating software designed to work with multiple database dialects.
In the early 2000s, there were quite a few open-source and commercial softwares that allowed to use either MySQL or PostgreSQL. However, it is not that common these days. Perhaps because the benefit of allowing user to choose between the different database dialects is marginal and the overhead of developing for multiple databases at once is significant.
Closing notes
I have summarised the key takeaways in the abstract of the article (see top of the article).
Just to wrap it up, this wasn’t a direct attack at Knex.js. The same feedback applies to any SQL builder. I don’t encourage you to actively migrate away from Knex.js. Instead, I presenting you with several considerations for weighting the best method of using SQL in your next project.
And don’t get me even started on ORMs. :-)
If you did find this interesting, I encourage you to read my next article about the design decisions behind Slonik SQL client.
